When the school year started last September, my wife and I had to decide whether we’re going to send our son to attend in-person or virtual school learning. As we were willing to send him to the in-person method, one of our major concerns was how to track the number of active covid-19 cases in his school. So, to not only rely on the School Board or School’s Principal communications, I decided to build a web scrapper that would check the Cases Report on the Provicen’s website every morning. It would search for the school name, the number of cases reported and send us an email with the results every day.
To start planning my web scrapper, some important information:
- The province reports the number of cases related to COVID-19 in schools and child care center everyday, around 10:30am. This information can be found here.
- If the school name is not found, it means that there are no cases reported. Otherwise, you will see the number of confirmed cases divided into Staff, Students or Non-Identified Individuals.
The Stack
I chose AWS as the platform to run my code and send notification e-mails. As the code is supposed to run once per day and is supposed to run very fast, I decided to use Lambda functions and SNS for the e-mail notifications. For the scheduling part, I created an EventBridge rule (cronjob schedule).
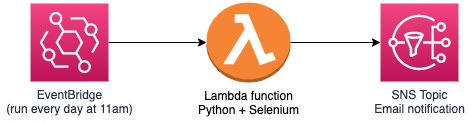
As I have previous web scrapping experience using Python and Selenium, these are the tools I chose for this project, but I know some people also prefer the combo Javascript + Puppeteer.
The Code
import time
import boto3
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pandas as pd
SCHOOL_NAME = "TYPE SCHOOL NAME HERE"
URL = "https://www.ontario.ca/page/covid-19-cases-schools-and-child-care-centres"
TIMEOUT = 3
SNS_TOPIC_ARN = "REPLACE WITH YOUR SNS TOPIC ARN"
def publish_sns(topic, subject, body):
sns = boto3.client('sns')
sns.publish(
TopicArn=topic,
Subject=subject,
Message=body
)
def check_school_cases():
chrome_options = Options()
chrome_options.headless = True
chrome_options.binary_location = '/opt/headless-chromium'
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--single-process')
chrome_options.add_argument('--disable-dev-shm-usage')
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get(URL)
time.sleep(TIMEOUT)
table = browser.find_element_by_id("en-table-school-list")
subject = "NO COVID CASES FOUND ON: " + SCHOOL_NAME
message = "School cases link: " + URL
if (SCHOOL_NAME in table.text):
subject = "ATTENTION! COVID CASES FOUND ON: " + SCHOOL_NAME
# print(SCHOOL_NAME + " found in Covid cases page.")
table = browser.find_element_by_tag_name('body')
html_table = table.get_attribute('outerHTML')
school_cases_table = pd.read_html(html_table)
school_row = school_cases_table[2].query('School.str.contains("'+ SCHOOL_NAME + '")', engine='python').index
message += '\n\n' + str(school_cases_table[2].loc[school_row[0]])
# print(message)
browser.quit()
publish_sns(SNS_TOPIC_ARN, subject, message)
def lambda_handler(event, context):
check_school_cases()
Leave a Reply